StoryMem: The Open Source Approach to Minute-Long AI Videos
StoryMem turns single-shot video models into multi-shot storytellers using visual memory. How it works, why it matters, and what it means for AI filmmaking.

Make AI images and video in your browser
Characters, video, photo packs. No GPU, no setup. Your first generation is free.
I've been waiting for someone to crack long-form AI video in a way that doesn't require training a massive new model from scratch. StoryMem just dropped a few days ago and it's exactly that solution.
Quick Answer: StoryMem is a research framework that transforms existing single-shot video diffusion models into multi-shot storytellers. It uses creative visual memory banks to maintain character and scene consistency across minute-long narrative videos without training new base models.
- Works on top of existing video diffusion models instead of replacing them
- Memory-to-Video (M2V) design stores keyframes for cross-shot consistency
- Generates videos shot-by-shot with maintained character identity
- Uses CLIP-based keyframe selection and HPSv3 quality filtering
- Published December 2025, making it bleeding-edge research
Why This Matters
Here's the problem with every video AI right now: they're great at 4-10 second clips. Sora, Runway Gen-3, Kling. All of them. But ask for a minute-long video with a consistent character doing multiple things? They fall apart.
The standard solution is "train a bigger model on more data." That costs millions of dollars and months of compute. StoryMem takes a different approach: use existing good models and add memory.
It's the kind of elegant solution that makes you wonder why nobody did it earlier.
How StoryMem Actually Works
The core insight is simple: humans remember what they saw. When you watch a movie and a character appears in scene 5, you remember what they looked like in scene 1. Current video models don't have this capability. Each generation starts fresh.
StoryMem adds a memory bank.
Step 1: Generate the first shot Use any pre-trained video diffusion model to create the opening shot based on your script.
Step 2: Extract keyframes The system picks the most semantically important frames using CLIP features. Not random frames, not every frame. The ones that best represent what happened.
Step 3: Store in memory bank These keyframes become the memory. Characters, settings, style cues are all captured here.
Step 4: Condition the next shot When generating shot 2, the model sees both the text description AND the memory bank. It knows what the character should look like.
Step 5: Repeat Each new shot adds to the memory. By the end, you have a coherent multi-shot video.
 The memory bank grows with each shot, maintaining consistency across the entire narrative
The memory bank grows with each shot, maintaining consistency across the entire narrative
Memory-to-Video (M2V) Architecture
The technical implementation is clever. They call it Memory-to-Video or M2V.
Two key components work together:
Memory Latent Concatenation The memory keyframes are encoded into the same latent space as the video model. They're literally concatenated to the noise input before sampling. The model sees "here's what came before" as a built-in constraint.
Negative RoPE Shift This is the elegant part. RoPE (Rotary Position Embedding) is how transformers understand sequence position. By applying a negative shift to memory tokens, the model interprets them as "things that happened in the past" rather than "things happening now."
Existing Image-to-Video models already understand temporal relationships. StoryMem just extends that understanding to include memory from previous shots.
Keyframe Selection Strategy
Not all frames deserve to be in memory. A blur during a camera move? Useless. A clear shot of the protagonist's face? Essential.
StoryMem uses CLIP features to measure semantic importance. Frames that strongly encode meaningful content get selected. Frames that are just transitions or noise get skipped.
They also add HPSv3 (Human Preference Score) filtering. This removes aesthetically poor frames from consideration. The memory bank only stores shots that look good AND carry meaning.
Free ComfyUI Workflows
Find free, open-source ComfyUI workflows for techniques in this article. Open source is strong.
The result is a compact memory that's both informative and reliable. No bloat, no garbage.
Comparison with Other Approaches
vs. Training Long-Form Models (Sora approach) Training from scratch requires massive data and compute. StoryMem works with any existing video model. You get long-form capability without the training cost.
vs. Simple Concatenation You could just stitch clips together. But without memory conditioning, you get obvious style and character drift between shots. StoryMem maintains coherence.
vs. Autoregressive Generation Some approaches generate frame-by-frame autoregressively. This causes error accumulation where small mistakes compound. StoryMem's shot-by-shot approach with memory is more stable.
| Approach | Training Required | Character Consistency | Multi-Shot Support |
|---|---|---|---|
| StoryMem | None (uses pretrained) | High | Native |
| Train from scratch | Massive | High | Native |
| Simple concatenation | None | Low | Manual |
| Autoregressive | Medium | Degrades over time | Partial |
What Can You Actually Generate?
Based on the paper, StoryMem produces:
- Minute-long narrative videos (12+ shots)
- Coherent character appearance across all shots
- Cinematic visual quality matching base model capability
- Script-driven generation with per-shot text control
The limiting factor is your base video model. If you're using WAN 2.2 as the foundation, you get WAN 2.2 quality. StoryMem adds multi-shot coherence, not fundamentally new visual capabilities.
This is a feature, not a bug. As base models improve, StoryMem automatically inherits those improvements.
Implications for AI Filmmaking
I've been messing with AI video for over a year now. The biggest friction point has always been consistency. You generate a beautiful 5-second clip, then the next clip looks like a completely different movie.
StoryMem points toward a solution that doesn't require waiting for Google or OpenAI to train trillion-parameter models. You can potentially run this locally with open-source video models.
Want to skip the complexity? Apatero gives you professional AI results instantly with no technical setup required.
Imagine combining this with:
- WAN 2.2 for high-quality base generation
- IPAdapter for even stronger character consistency
- Script-driven prompting for narrative control
That's a legitimate short film workflow using entirely open-source tools.
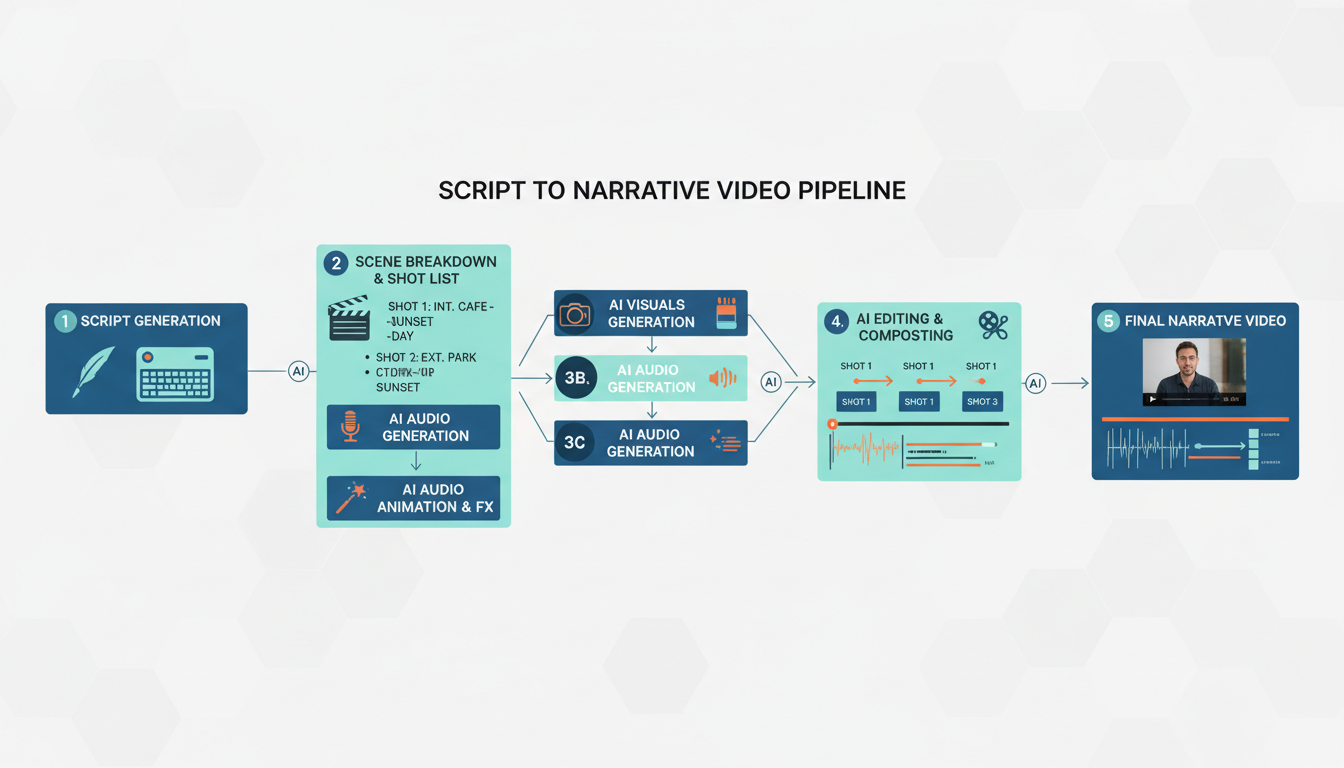 StoryMem enables script-to-video pipelines with maintained character consistency
StoryMem enables script-to-video pipelines with maintained character consistency
Current Limitations
Being honest about what StoryMem can't do yet:
No official implementation (yet) The paper dropped December 22, 2025. Code may be coming but isn't public at time of writing.
Memory growth Each shot adds to memory. For very long videos, the memory bank could become unwieldy. The paper mentions compact storage strategies but doesn't fully solve this for arbitrary length content.
Single-model training While StoryMem doesn't require training new base models, it does require training the M2V conditioning layer. Not from-scratch training, but still additional training.
Camera limitations The memory stores keyframes, not camera parameters. Complex camera moves that should match across shots aren't explicitly enforced.
What Open Source Alternatives Exist?
If you want multi-shot consistency today:
Earn Up To $1,250+/Month Creating Content
Join our exclusive creator affiliate program. Get paid per viral video based on performance. Create content in your style with full creative freedom.
Open-Sora 2.0 HPC-AI Tech's open implementation. Doesn't have StoryMem's memory architecture but produces good quality and is fully open source.
WAN 2.2 with IPAdapter Manual but works. Use IPAdapter face embeddings across clips. Requires careful prompt engineering but achieves consistency.
Simple Memory Conditioning You can hack together basic memory by conditioning each generation on the final frame of the previous generation. Less sophisticated than StoryMem but functional.
For Apatero.com, we're exploring how to integrate memory-based consistency into our video workflows. The StoryMem approach is directly applicable to what we're building.
When Will This Be Usable?
My prediction: implementations within 1-2 months.
The paper provides enough detail that motivated researchers can reproduce it. HuggingFace and ComfyUI integrations typically follow major papers within weeks.
Watch for:
- GitHub repo release from the original authors
- ComfyUI custom node implementations
- Integration into existing video pipelines like SVD or AnimateDiff
The technique is elegant enough that it will be widely adopted. Just a matter of time.
FAQ
Is StoryMem actually open source? The research paper is public. Implementation code isn't released yet but the technique is documented thoroughly enough to reproduce.
Can I run this locally? Eventually yes. It adds minimal overhead to existing video models. If you can run WAN or SVD locally, you'll be able to run StoryMem.
Does this compete with Sora? Not directly. Sora is a trained model. StoryMem is a framework that works with any video model. They're complementary, not competitive.
How does the memory handle character changes? Script descriptions can indicate character changes. The memory conditioning is additive, not restrictive. New characters can appear without conflicting with existing memory.
What video models does it work with? In principle, any diffusion-based video model. The paper tests on specific architectures but the approach is general.
Is the quality as good as native long-form models? Quality matches the base model. Coherence is the improvement. If your base model produces great 5-second clips, StoryMem produces great minute-long narratives at that same quality level.
What scripts work best? Clear per-shot descriptions with consistent character names. The system needs to know when the same character appears across shots to apply memory correctly.
What This Means for the Future
The broader implication is exciting: you don't always need to train new models to get new capabilities. Sometimes clever engineering on top of existing models is enough.
StoryMem demonstrates that long-form video isn't a training problem. It's a memory problem. Solve memory, and existing models suddenly become much more capable.
I expect we'll see more research in this direction. Adding memory, reasoning, or planning layers to existing generative models rather than training ever-larger monolithic systems.
For practical use, this means the path to local, open-source AI filmmaking just got a lot shorter. We're not waiting for OpenAI to release Sora weights. We're building equivalent capability from components we can actually access.
That's the kind of progress I get excited about.
Make AI images and video in your browser
Characters, video, photo packs. No GPU, no setup. Your first generation is free.
Related Articles

AI Video Denoising and Restoration: Complete Guide to Fixing Noisy Footage (2025)
Master AI video denoising and restoration techniques. Fix grainy footage, remove artifacts, restore old videos, and enhance AI-generated content with professional tools.
AI Video Generator Comparison 2025: WAN vs Kling vs Runway vs Luma vs Apatero
In-depth comparison of the best AI video generators in 2025. Features, pricing, quality, and which one is right for your needs including AI capabilities.

AI Video Multi-Clip Editing: Complete Workflow for Smooth Transitions (2025)
Master multi-clip AI video editing workflows. Learn to combine LTX-2, WAN, and Hunyuan clips into cohesive videos with smooth transitions and consistent style.