Qwen 3VL Vision Model Complete Guide: AI Image Understanding in 2026
Master Qwen 3VL, Alibaba's vision-language model for image understanding, OCR, and visual reasoning. Complete setup, use cases, and comparison guide.

Vision-language models have transformed how AI understands images. While GPT-4V grabbed headlines, Qwen 3VL (also known as Qwen2-VL) offers comparable capabilities as an open source alternative that runs locally. For developers and researchers needing powerful image understanding without API costs, this model deserves serious attention.
I've integrated Qwen 3VL into multiple projects over the past few months, from automated image captioning to document analysis systems. The capabilities continually surprise me, handling tasks I expected only proprietary models could manage.
This guide walks through everything from basic setup to advanced applications, helping you use Qwen 3VL's full potential.
Quick Answer: Qwen 3VL understands images, answers questions about them, reads text (OCR), and performs visual reasoning. Available in 2B, 7B, and 72B sizes, the 7B version runs on consumer GPUs while providing excellent capability. It matches GPT-4V on many benchmarks and excels particularly at document understanding and multilingual OCR.
:::tip[Key Takeaways]
- Follow the step-by-step process for best results with qwen 3vl vision model complete guide: ai image understanding in 2026
- Start with the basics before attempting advanced techniques
- Common mistakes are easy to avoid with proper setup
- Practice improves results significantly over time :::
- Understanding Qwen 3VL capabilities
- Installation and setup methods
- Practical use cases and applications
- Comparison with GPT-4V and Claude Vision
- Optimization and advanced techniques
What Qwen 3VL Can Do
Vision-language models combine image understanding with language generation. Qwen 3VL processes images alongside text prompts to answer questions, describe scenes, extract information, and reason about visual content.
Core Capabilities
Image Description: Generate detailed captions and descriptions of image contents. Identifies objects, scenes, activities, and relationships.
Visual Question Answering: Answer specific questions about images. What color is the car? How many people are present? What is the person doing?
OCR and Document Understanding: Read text from images with high accuracy. Handles various fonts, orientations, and languages. Understands document structure beyond just character recognition.
Visual Reasoning: Make inferences about images requiring understanding beyond surface-level description. Why might this situation be dangerous? What will likely happen next?
Multi-image Comparison: Analyze multiple images together. Compare differences, track changes, synthesize information across images.
 Qwen 3VL handles diverse vision-language tasks
Qwen 3VL handles diverse vision-language tasks
Model Versions
Qwen2-VL-2B: Smallest version. Runs on modest hardware including some laptops. Good for basic tasks where resources are limited.
Qwen2-VL-7B: Best balance of capability and efficiency. Runs on consumer GPUs with 12GB+ VRAM. Handles most practical applications well.
Qwen2-VL-72B: Maximum capability. Requires significant hardware but approaches frontier model performance.
Setting Up Qwen 3VL
Multiple deployment options suit different needs:
Using Transformers
from transformers import Qwen2VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
model = Qwen2VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2-VL-7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct")
Direct Hugging Face integration provides maximum flexibility for custom applications.
Using Ollama
ollama pull qwen2-vl:7b
Ollama simplifies deployment with automatic model management. Great for experimentation and simple applications.
Using vLLM
For high-throughput production deployments, vLLM offers optimized inference:
vllm serve Qwen/Qwen2-VL-7B-Instruct
Provides OpenAI-compatible API for easy integration.
Hardware Requirements
Qwen2-VL-2B:
- 4GB VRAM minimum
- 8GB system RAM
- Suitable for laptop GPUs
Qwen2-VL-7B:
- 12GB VRAM recommended
- 16GB system RAM
- Consumer GPUs (RTX 3080, 4070 or better)
Qwen2-VL-72B:
- 80GB+ VRAM (A100 or multi-GPU)
- 128GB+ system RAM
- Server-grade hardware
Practical Applications
Document Processing
Qwen 3VL excels at extracting information from documents:
Invoice Processing: Extract vendor names, amounts, dates, line items from scanned invoices. Handles various formats without template-specific configuration.
Receipt Scanning: Read receipts for expense tracking. Handles messy prints and faded text reasonably well.
Free ComfyUI Workflows
Find free, open-source ComfyUI workflows for techniques in this article. Open source is strong.
Form Understanding: Extract data from filled forms. Understands checkbox states, handwritten entries, and structured layouts.
Academic Papers: Summarize figures, extract key information from charts and tables.
Content Moderation
Automatically analyze images for content issues:
Safety Screening: Identify potentially inappropriate content.
Brand Compliance: Check marketing materials meet guidelines.
Accessibility: Generate alt text descriptions for images.
E-commerce Applications
Product Cataloging: Generate descriptions from product images.
Quality Control: Identify defects or issues in product photos.
Inventory Management: Read product codes, count items.
Research and Analysis
Scientific Images: Describe charts, graphs, experimental results.
Medical Imaging: Support (not replace) analysis of scans and images.
Want to skip the complexity? Apatero gives you professional AI results instantly with no technical setup required.
Satellite Imagery: Identify features, changes over time.
Comparison with Alternatives
Qwen 3VL vs GPT-4V
Qwen advantages:
- Free to use locally
- No API costs or rate limits
- Complete privacy
- Customizable through fine-tuning
GPT-4V advantages:
- Better nuanced understanding
- Stronger general reasoning
- More reliable on edge cases
- Better instruction following
For most practical applications, Qwen 3VL-72B matches GPT-4V. Smaller versions handle many tasks adequately at fraction of the cost.
Qwen 3VL vs Claude Vision
Similar trade-offs to GPT-4V comparison. Claude excels at detailed analysis and longer explanations. Qwen offers cost advantages and privacy benefits.
Qwen 3VL vs LLaVA
Both are open source vision models. Qwen generally outperforms LLaVA on benchmarks, particularly for document understanding and OCR. LLaVA has larger community and more fine-tuned variants available.
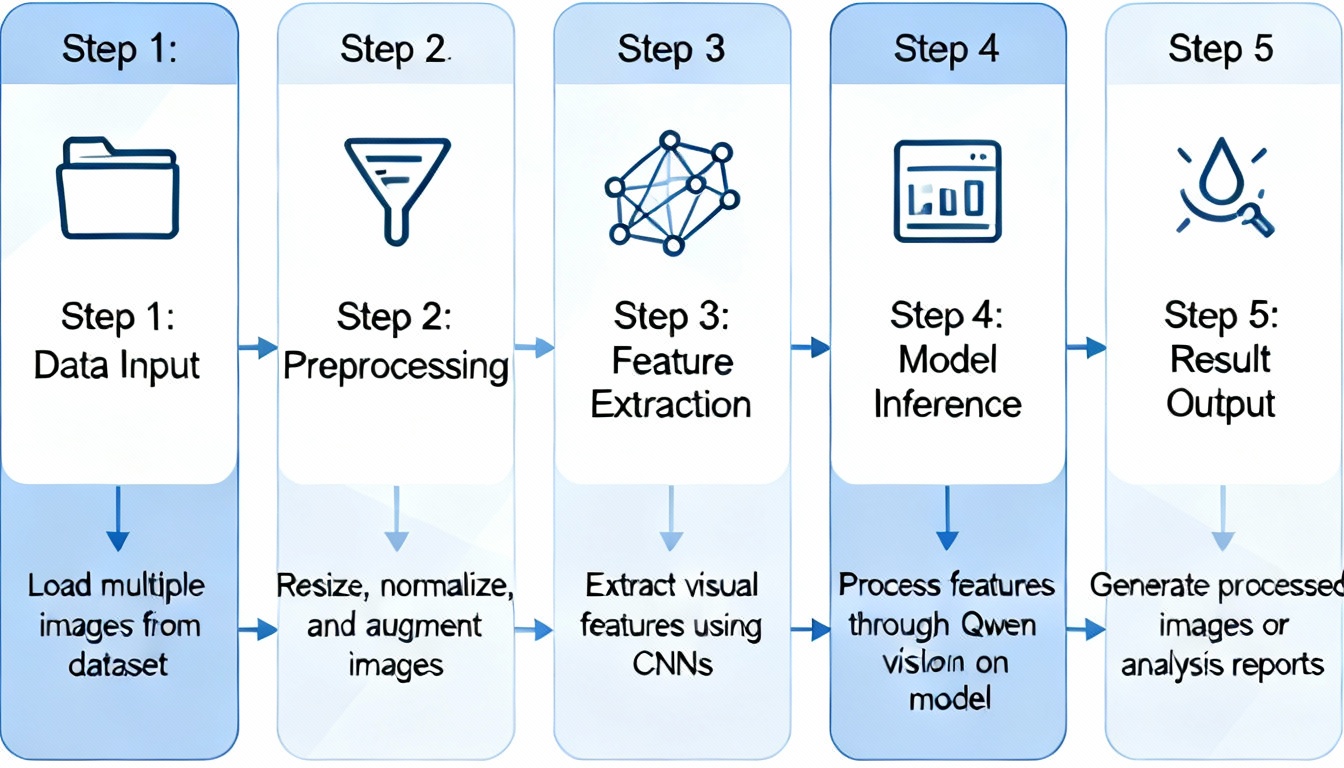
Advanced Techniques
Multi-image Processing
Qwen 3VL handles multiple images in single queries:
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "image1.jpg"},
{"type": "image", "image": "image2.jpg"},
{"type": "text", "text": "Compare these two images"}
]
}
]
Useful for before/after comparisons, finding differences, or synthesizing information across images.
Video Understanding
Qwen 3VL processes video by analyzing key frames:
messages = [
{
"role": "user",
"content": [
{"type": "video", "video": "video.mp4"},
{"type": "text", "text": "Describe what happens in this video"}
]
}
]
Extracts key frames automatically and provides coherent video descriptions.
Earn Up To $1,250+/Month Creating Content
Join our exclusive creator affiliate program. Get paid per viral video based on performance. Create content in your style with full creative freedom.
Structured Output
For integration into pipelines, request structured JSON output:
"Analyze this receipt and return JSON with fields: store_name, date, items (array with name and price), total"
Enables automated processing of extracted information.
Fine-tuning for Specific Domains
For specialized applications, fine-tune Qwen 3VL on domain-specific data:
- Medical imaging analysis
- Specific document formats
- Industry-specific visual inspection
- Custom captioning styles
LoRA fine-tuning makes this accessible on consumer hardware.
Optimization Tips
Memory Efficiency
Quantization: 4-bit or 8-bit quantization significantly reduces VRAM requirements with modest quality trade-off.
Flash Attention: Enable flash attention for faster, more memory-efficient processing.
Batch processing: Process multiple images together more efficiently than one-by-one.
Speed Optimization
Lower resolution for simple tasks: Full resolution isn't always necessary. Reduce image size when detail isn't critical.
Async processing: Process images in background while handling other tasks.
Model caching: Keep model loaded for repeated inference rather than reloading.
Quality Optimization
Clear prompts: Specific questions get better answers than vague ones.
Appropriate model size: Larger models for complex reasoning, smaller for simple tasks.
Retry logic: For critical applications, retry and compare multiple outputs.
Frequently Asked Questions
What's the difference between Qwen2-VL and Qwen 3VL?
They refer to the same model family. "Qwen2-VL" is the official naming while "Qwen 3VL" is commonly used for the third major version.
Can Qwen 3VL run on CPU only?
Technically yes, but extremely slowly. Even the 2B model benefits enormously from GPU acceleration.
How accurate is the OCR capability?
Very good for printed text in common fonts and languages. Handles handwriting with moderate accuracy. Performance degrades on unusual fonts or severely degraded images.
Can I use Qwen 3VL commercially?
Yes, it uses Apache 2.0 license allowing commercial use.
How does latency compare to cloud APIs?
Local inference on good hardware can be faster than API calls. Depends on hardware, model size, and image complexity.
Does it support all languages for OCR?
Strong support for English and Chinese. Other languages work but with varying accuracy. Multilingual documents work well.
Can it process AI images?
Qwen 3VL doesn't have built-in content filtering like commercial APIs. Use responsibly and implement your own filtering if needed.
What image formats does it accept?
Standard formats: JPEG, PNG, WebP, GIF. Videos supported for keyframe analysis.
Conclusion
Qwen 3VL brings frontier vision-language capabilities to open source. For developers needing image understanding without cloud dependencies, it provides exceptional value.
The 7B version handles most practical applications while running on consumer hardware. Document processing, automated captioning, visual question answering, and content analysis all work impressively.
Getting started takes minutes with Ollama or the Transformers library. The investment in learning these tools pays dividends across projects requiring visual AI capabilities.
For text-only applications of Qwen, see our comprehensive Qwen 2.5 guide. For integrating vision capabilities into content creation workflows, explore how can complement analysis tools.
Ready to Create Your AI Influencer?
Join 115 students mastering ComfyUI and AI influencer marketing in our complete 51-lesson course.
Related Articles

Adobe Firefly vs Midjourney vs Ideogram 2026: Which Wins
Brand-safe licensing, scroll-stopping aesthetics, or text rendering. Three tools optimized for three different jobs, tested against real briefs.

AI Art Market Statistics 2025: Industry Size, Trends, and Growth Projections
Comprehensive AI art market statistics including market size, creator earnings, platform data, and growth projections with 75+ data points.

AI Automation Tools: Transform Your Business Workflows in 2025
Discover the best AI automation tools to transform your business workflows. Learn how to automate repetitive tasks, improve efficiency, and scale operations with AI.