Qwen 2.5 Complete Guide: Alibaba's Powerful Open Source AI Model Explained
Everything you need to know about Qwen 2.5, Alibaba's latest open source AI model. Learn capabilities, installation, use cases, and how it compares to GPT-4 and Claude.

Qwen 2.5 represents Alibaba's most significant contribution to open source AI. While Western media focuses on GPT-4 and Claude, Qwen has quietly become one of the most capable freely available language models, matching or exceeding closed-source competitors in many benchmarks.
For developers, researchers, and enthusiasts who want powerful AI without API costs or usage restrictions, Qwen 2.5 offers a compelling option. I've been running Qwen locally for several months, testing it against other models and integrating it into various projects.
This guide covers everything from basic understanding to advanced deployment, helping you decide if Qwen 2.5 fits your needs and how to make the most of it.
Quick Answer: Qwen 2.5 is Alibaba's open source large language model available in sizes from 0.5B to 72B parameters. The 7B and 14B versions run on consumer hardware while matching or exceeding GPT-3.5 performance. The 72B version competes with GPT-4 on many tasks. It's free to use commercially and can run completely locally for privacy-sensitive applications.
- Qwen 2.5 offers 0.5B to 72B parameter versions
- Open source with commercial-friendly license
- Competitive performance with GPT-4 on many benchmarks
- Runs locally on consumer hardware (smaller versions)
- Excellent for coding, math, and Chinese language tasks
Understanding Qwen 2.5
Qwen (通义千问) emerged from Alibaba Cloud's AI research division. The 2.5 release builds on previous versions with significant improvements in reasoning, coding, and multilingual capabilities.
Model Family Overview
Qwen 2.5 comes in multiple sizes to balance capability against resource requirements:
Qwen2.5-0.5B: Tiny model for edge devices and embedded applications. Limited capability but runs anywhere.
Qwen2.5-1.5B: Small but functional. Good for simple tasks on modest hardware.
Qwen2.5-3B: Sweet spot for mobile devices. Surprisingly capable for its size.
Qwen2.5-7B: Consumer GPU friendly. Matches GPT-3.5 on most tasks.
Qwen2.5-14B: Excellent quality-to-resource ratio. Best choice for most local deployments.
Qwen2.5-32B: High capability for users with strong hardware.
Qwen2.5-72B: Flagship model competing with GPT-4. Requires significant resources.
 Qwen 2.5 offers models across the capability spectrum
Qwen 2.5 offers models across the capability spectrum
Key Capabilities
Reasoning and Analysis: Improved logical reasoning over previous versions. Handles complex multi-step problems well.
Coding: Excellent programming assistance across languages. Particularly strong in Python, JavaScript, and C++.
Mathematics: Notable strength in mathematical reasoning. Solves problems from basic arithmetic through advanced calculus.
Multilingual: Supports 29+ languages with particular strength in Chinese-English tasks.
Long Context: Extended context versions handle up to 128K tokens, enabling analysis of entire documents.
How It Compares
Against GPT-4:
- Qwen2.5-72B matches GPT-4 on many benchmarks
- GPT-4 maintains advantages in nuanced reasoning and creative tasks
- Qwen excels in mathematical and coding benchmarks
- GPT-4 better at following complex, ambiguous instructions
Against Claude:
- Similar pattern to GPT-4 comparison
- Claude stronger in long-form writing and nuanced analysis
- Qwen competitive on structured tasks and code
Against Open Source Alternatives:
- Outperforms LLaMA 3 in most benchmarks
- Competitive with Mixtral on reasoning tasks
- Best-in-class among open models for coding
Running Qwen Locally
One of Qwen's primary advantages is running completely locally, ensuring privacy and eliminating API costs.
Hardware Requirements
Qwen2.5-7B (Q4 quantized):
- 8GB VRAM minimum (NVIDIA GPU)
- 16GB system RAM
- ~4GB storage
Qwen2.5-14B (Q4 quantized):
- 12GB VRAM recommended
- 32GB system RAM
- ~8GB storage
Qwen2.5-72B (Q4 quantized):
- 48GB+ VRAM (multiple GPUs or A100)
- 64GB+ system RAM
- ~40GB storage
Installation Methods
Several frameworks support Qwen deployment:
Ollama (Easiest):
ollama pull qwen2.5:7b
ollama run qwen2.5:7b
Ollama handles model downloading, quantization selection, and provides a simple interface. Best for beginners.
Free ComfyUI Workflows
Find free, open-source ComfyUI workflows for techniques in this article. Open source is strong.
LM Studio (GUI): Download LM Studio, search for Qwen 2.5 models, and click to install. Provides a ChatGPT-like interface for local models.
vLLM (Production): For high-throughput applications, vLLM offers optimized inference with API compatibility.
Transformers (Flexible):
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-7B-Instruct")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B-Instruct")
Direct Hugging Face integration for custom applications.
Quantization Options
Quantization reduces memory requirements with some quality trade-off:
Q8: Near-original quality. Recommended when resources allow. Q6_K: Excellent balance. Recommended for most users. Q4_K_M: Good quality reduction. Best for limited VRAM. Q4_0: Maximum compression. Noticeable quality loss.
For Qwen2.5-7B, Q6_K runs on 8GB VRAM with excellent quality. For 14B, Q4_K_M fits on 12GB VRAM.
Practical Use Cases
Qwen excels in specific applications:
Coding Assistant
Qwen handles programming tasks impressively:
- Code generation from descriptions
- Bug identification and fixes
- Code explanation and documentation
- Test generation
- Refactoring suggestions
For developers, Qwen2.5-14B provides GPT-4-class coding assistance running locally.
Document Analysis
The long-context versions enable:
- Summarizing lengthy documents
- Extracting specific information
- Comparing multiple documents
- Answering questions about content
128K context handles most practical document lengths.
Chinese-English Applications
Qwen's bilingual strength suits:
Want to skip the complexity? Apatero gives you professional AI results instantly with no technical setup required.
- Translation tasks
- Cross-lingual information retrieval
- Content localization
- Chinese market research
Better Chinese understanding than most Western models.
Research and Learning
For educational and research purposes:
- Mathematical problem solving
- Concept explanation
- Research summarization
- Study assistance
The math capabilities particularly impress for STEM applications.
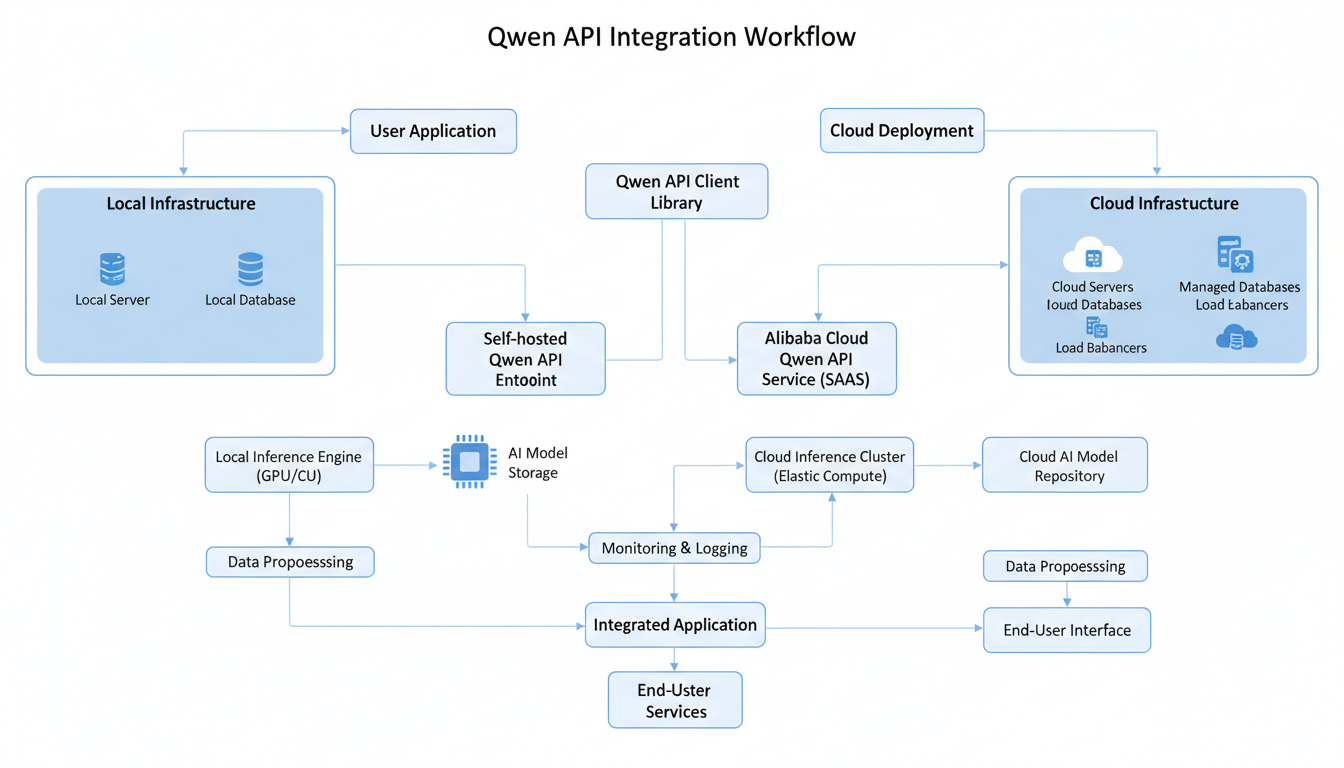
API Integration
For applications needing Qwen access, several options exist:
Alibaba Cloud API
Official API access through Alibaba Cloud:
- Pay-per-token pricing
- High reliability
- All model sizes available
- Enterprise support
Requires Alibaba Cloud account and may have regional restrictions.
OpenRouter
Access multiple AI models through unified API:
- Qwen included alongside GPT-4, Claude
- Simple integration
- Pay-per-use pricing
Good for applications that might switch between models.
Local API
Run Qwen locally with OpenAI-compatible API:
# Using vLLM
vllm serve Qwen/Qwen2.5-7B-Instruct
# Using Ollama
ollama serve
Replace OpenAI API calls with local endpoint for zero-cost inference.
Advanced Features
Function Calling
Qwen 2.5 supports function calling similar to GPT-4:
- Define functions with schemas
- Model decides when to call functions
- Returns structured function calls
- Enables tool use and agent behavior
Implementation matches OpenAI's function calling format for compatibility.
Earn Up To $1,250+/Month Creating Content
Join our exclusive creator affiliate program. Get paid per viral video based on performance. Create content in your style with full creative freedom.
Structured Output
Generate JSON and other structured formats:
- Consistent schema following
- Better than instruction-based structure
- Useful for data extraction
- Enables pipeline integration
System Prompts
Customize behavior through system prompts:
- Define assistant personality
- Set response constraints
- Establish context
- Control output format
System prompt support matches industry standards.
Fine-Tuning Qwen
For specialized applications, fine-tuning adapts Qwen to your specific needs.
When to Fine-Tune
Consider fine-tuning when:
- Base model doesn't understand your domain
- Consistent output format required
- Specialized vocabulary needed
- Performance on specific tasks matters
Don't fine-tune for general improvements. Base model already handles general tasks well.
LoRA Fine-Tuning
Low-rank adaptation offers efficient fine-tuning:
- Trains only small adapter weights
- Much faster than full fine-tuning
- Requires less hardware
- Results can match full fine-tuning
With good data, LoRA training takes hours rather than days.
Data Preparation
Quality training data determines results:
- Collect examples of desired behavior
- Format consistently (instruction-response pairs)
- Diverse coverage of target use cases
- At least 1,000 examples recommended
Poor data produces poor results regardless of technique.
Troubleshooting Common Issues
Out of Memory Errors
Symptoms: CUDA out of memory, crashes during inference.
Solutions:
- Use smaller model version
- Apply more aggressive quantization
- Reduce batch size
- Free up VRAM from other applications
Slow Generation
Symptoms: Very slow token generation, unresponsive inference.
Solutions:
- Ensure GPU acceleration is active
- Use optimized inference framework (vLLM)
- Check for CPU fallback
- Reduce context length if possible
Poor Quality Outputs
Symptoms: Nonsensical, repetitive, or wrong answers.
Solutions:
- Adjust temperature and sampling parameters
- Improve prompt clarity
- Try larger model version
- Check for corrupted model download
Frequently Asked Questions
Is Qwen 2.5 free to use commercially?
Yes, Qwen 2.5 uses Apache 2.0 license allowing commercial use without restrictions.
How does Qwen 2.5 compare to GPT-4?
Qwen2.5-72B matches GPT-4 on many benchmarks. Smaller versions are more comparable to GPT-3.5. GPT-4 maintains advantages in nuanced reasoning.
Can Qwen 2.5 run on my computer?
Qwen2.5-7B runs on 8GB VRAM GPUs. Larger versions need more resources. Check hardware requirements against your setup.
What languages does Qwen support?
29+ languages including English, Chinese, Spanish, French, German, Japanese, Korean, and more.
Is Qwen good for coding?
Excellent. Qwen's coding capabilities rival GPT-4, especially for Python, JavaScript, and C++.
Can I fine-tune Qwen for my application?
Yes, Qwen supports fine-tuning. LoRA training makes this accessible on consumer hardware.
Does Qwen support vision or images?
Qwen2-VL handles vision tasks. The base Qwen 2.5 is text-only. See our Qwen 3VL guide for vision capabilities.
How private is local Qwen deployment?
Completely private. Local deployment keeps all data on your machine with no external transmission.
Conclusion
Qwen 2.5 democratizes access to GPT-4-class AI capabilities. For developers, researchers, and power users willing to run models locally, it provides exceptional value with zero ongoing costs.
The model shines for coding, mathematics, and Chinese-English applications. General reasoning and creative tasks work well but don't quite match the best closed-source models.
Getting started is straightforward with tools like Ollama or LM Studio. The 7B and 14B versions run on reasonable consumer hardware while delivering impressive capability.
As open source AI continues advancing, Qwen represents what's possible when major tech companies contribute freely to the ecosystem. Whether for commercial applications, research, or personal projects, Qwen 2.5 deserves serious consideration.
For vision AI applications, explore our guide to Qwen 3VL, which extends these capabilities to image understanding.
Ready to Create Your AI Influencer?
Join 115 students mastering ComfyUI and AI influencer marketing in our complete 51-lesson course.
Related Articles

Adobe Firefly vs Midjourney vs Ideogram 2026: Which Wins
Brand-safe licensing, scroll-stopping aesthetics, or text rendering. Three tools optimized for three different jobs, tested against real briefs.

AI Art Market Statistics 2025: Industry Size, Trends, and Growth Projections
Comprehensive AI art market statistics including market size, creator earnings, platform data, and growth projections with 75+ data points.

AI Automation Tools: Transform Your Business Workflows in 2025
Discover the best AI automation tools to transform your business workflows. Learn how to automate repetitive tasks, improve efficiency, and scale operations with AI.