HiDream-I1: The Sparse DiT That's Outperforming Flux and DALL-E
HiDream-I1 is a 17B parameter sparse DiT model with Mixture-of-Experts architecture. Complete guide to capabilities, benchmarks, and practical usage.

A new contender has emerged in the image generation space, and the benchmarks are impressive. HiDream-I1, a 17 billion parameter model with a sparse Diffusion Transformer architecture, is posting numbers that beat Flux.1-dev and DALL-E 3 on multiple evaluation metrics. And it's MIT licensed.
Quick Answer: HiDream-I1 is a 17B parameter sparse Diffusion Transformer using Mixture-of-Experts (MoE) architecture that achieves state-of-the-art performance on GenEval (0.83) and DPG-Bench (85.89) while supporting efficient inference through dynamic expert routing. Available in Full, Dev, and Fast variants under MIT license.
- 17 billion parameters with sparse Mixture-of-Experts architecture
- Outperforms Flux.1-dev, DALL-E 3, and Stable Diffusion 3 on benchmarks
- Hybrid text encoding: Long-CLIP + T5-XXL + Llama 3.1 8B
- Three variants: Full (max quality), Dev (balanced), Fast (speed optimized)
- MIT license enables commercial use and modification
- Extended to editing (HiDream-E1) and agent capabilities (HiDream-A1)
What Makes HiDream-I1 Different
Most diffusion transformers (DiT) use dense architectures where every parameter activates for every input. HiDream-I1 uses a sparse architecture with Mixture-of-Experts (MoE), meaning it dynamically routes different inputs through different expert modules based on what the input actually needs.
This matters for two reasons:
Efficiency: You get 17B parameter quality without 17B parameter compute. Only relevant experts activate for each generation.
Specialization: Different experts develop different capabilities. Some become better at faces. Others at text rendering. Others at spatial reasoning. The routing learns to use the right expert for each input.
Architecture Detailed look
HiDream-I1 uses a dual-stream then single-stream architecture:
Dual-Stream Stage
Two separate encoders independently process image and text tokens. This decoupled design lets each modality develop rich representations without early fusion constraints.
Single-Stream Stage
After initial processing, streams merge for multi-modal interaction. This is where the model learns relationships between text descriptions and visual features.
Dynamic MoE Throughout
Both stages incorporate dynamic Mixture-of-Experts. The key word is "dynamic" - expert assignment changes based on input characteristics, not fixed routing patterns.
This architectural choice creates remarkable balance between computational efficiency and output quality. You're not throwing compute at problems that don't need it.
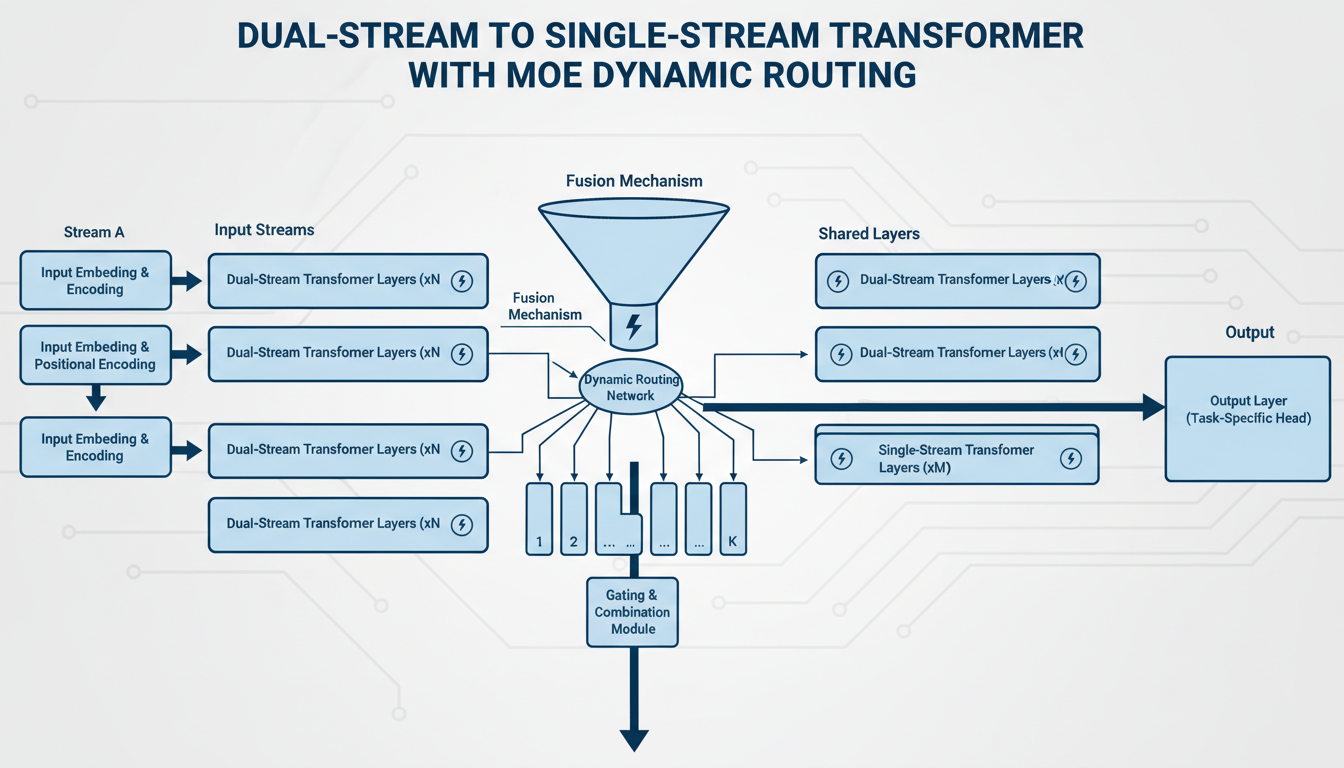 Dual-stream to single-stream architecture with dynamic MoE routing
Dual-stream to single-stream architecture with dynamic MoE routing
Text Encoding Stack
HiDream-I1 uses a hybrid text encoding approach with three components:
Long-CLIP: Extended context CLIP for better text-image alignment on longer prompts.
T5-XXL: The powerful encoder from Google's T5 family for semantic understanding.
Llama 3.1 8B: Meta's LLM providing additional language comprehension.
This triple-encoder approach handles everything from simple prompts to complex scene descriptions. Each encoder contributes different strengths, and the combination produces strong prompt adherence.
Benchmark Performance
The numbers speak for themselves:
GenEval Results
| Model | Overall | Single Obj | Two Obj | Counting | Colors | Position |
|---|---|---|---|---|---|---|
| HiDream-I1 | 0.83 | 1.00 | 0.74 | 0.79 | 0.86 | 0.18 |
| Flux.1-dev | 0.67 | 0.98 | 0.73 | 0.37 | 0.80 | 0.14 |
| DALL-E 3 | 0.67 | 0.96 | 0.74 | 0.47 | 0.85 | 0.15 |
| SD3 Medium | 0.74 | 0.98 | 0.74 | 0.63 | 0.85 | 0.13 |
Perfect single object generation (1.00) and leading counting accuracy (0.79) show the model's precision.
DPG-Bench Results
| Model | Overall | Global | Entity | Attribute | Relation |
|---|---|---|---|---|---|
| HiDream-I1 | 85.89 | 87.02 | 89.11 | 84.47 | 93.74 |
| Flux.1-dev | 83.65 | 86.47 | 88.15 | 81.75 | 88.79 |
| SD3 Medium | 84.08 | 86.18 | 89.08 | 81.54 | 87.01 |
That relation comprehension score (93.74) is exceptional. The model understands how objects relate to each other in scenes.
Human Preference (HPSv2.1)
| Model | Score |
|---|---|
| HiDream-I1 | 33.82 |
| Flux.1-dev | 32.47 |
| DALL-E 3 | 31.44 |
Humans prefer HiDream-I1 outputs over both major competitors.
Model Variants
HiDream-I1 ships in three variants:
HiDream-I1-Full
Maximum quality variant. Full 17B parameters, no distillation, best possible output.
Use when: Quality is paramount and compute time is acceptable.
HiDream-I1-Dev
Distilled version with accelerated inference. Maintains most quality while being faster.
Use when: Good balance of speed and quality needed. Best for iteration.
HiDream-I1-Fast
Aggressive distillation for speed-focused applications.
Free ComfyUI Workflows
Find free, open-source ComfyUI workflows for techniques in this article. Open source is strong.
Use when: Speed matters most, quality can be slightly reduced.
All three variants are available. Choose based on your specific use case requirements.
 Quality comparison: Full variant on left, Dev center, Fast on right
Quality comparison: Full variant on left, Dev center, Fast on right
Extended Capabilities
The HiDream team has extended the base model to additional use cases:
HiDream-E1 (Editing)
Instruction-based image editing using the same architecture. Give it an image and natural language instructions for modifications.
Examples:
- "Remove the person in the background"
- "Change the car color to red"
- "Add rain to the scene"
The sparse DiT architecture translates well to editing tasks.
HiDream-A1 (Agent)
A comprehensive image agent capable of fully interactive image creation and refinement. Not just generate-and-done, but iterative collaboration.
This points to where image generation is heading: conversational creation rather than single-shot prompting.
Practical Usage
Hardware Requirements
| Variant | Minimum VRAM | Recommended |
|---|---|---|
| Full | 24GB | 48GB |
| Dev | 16GB | 24GB |
| Fast | 12GB | 16GB |
The sparse architecture helps, but 17B parameters still need memory. Dev variant is the practical choice for most users.
Inference Speed
On an A100:
- Full: ~15 seconds per image
- Dev: ~8 seconds per image
- Fast: ~4 seconds per image
Significantly faster than equivalent dense models at same parameter count.
Want to skip the complexity? Apatero gives you professional AI results instantly with no technical setup required.
Prompt Style
HiDream-I1 responds well to both styles:
Natural language:
A serene mountain lake at sunset, with pine trees reflecting in the
still water and clouds painted in shades of orange and purple.
Structured prompts:
mountain lake, sunset lighting, pine trees, water reflection,
orange clouds, purple sky, peaceful atmosphere, 8k quality
The hybrid text encoder stack handles both approaches. Use what fits your workflow.
ComfyUI Integration
HiDream-I1 has community nodes available for ComfyUI integration:
Installation:
- Clone HiDream nodes to custom_nodes folder
- Download model from HuggingFace to models/diffusion_models/
- Restart ComfyUI
- Use HiDream Load and Sample nodes
The workflow follows standard diffusion model patterns. If you've used Flux or SD3 nodes, HiDream works similarly.
For ComfyUI workflows, the sparse architecture might require different batch handling compared to dense models.
Comparison with Flux
Since Flux is the current community favorite, direct comparison matters:
| Feature | HiDream-I1 Full | Flux.1-dev |
|---|---|---|
| Parameters | 17B (sparse) | 12B (dense) |
| GenEval Score | 0.83 | 0.67 |
| Counting Accuracy | 0.79 | 0.37 |
| License | MIT | Non-commercial |
| Edit Variant | Yes (E1) | No |
HiDream wins on benchmarks and licensing. Flux may still have edge cases where it performs better, but the overall numbers favor HiDream.
The counting accuracy difference (0.79 vs 0.37) is dramatic. If you need accurate object counting in generations, HiDream is significantly better.
Earn Up To $1,250+/Month Creating Content
Join our exclusive creator affiliate program. Get paid per viral video based on performance. Create content in your style with full creative freedom.
Licensing and Commercial Use
MIT license means:
- Free to use commercially
- Free to modify
- Free to distribute
- No attribution required (though appreciated)
This is more permissive than most competitive models. Flux.1-dev is non-commercial. SD3 has its own license complexity. HiDream just says "do what you want."
For production at Apatero.com, permissive licensing removes friction. You don't need to track usage or worry about compliance.
Limitations
Being honest about where HiDream-I1 has room to grow:
Position accuracy: GenEval position score of 0.18 is lower than other metrics. Precise spatial positioning still challenging.
Text rendering: Like most diffusion models, text in images remains imperfect. For text-in-image needs, specialized models remain better.
VRAM requirements: Full variant needs substantial memory. Not for 8GB GPU users without significant optimization.
Ecosystem maturity: Newer than Flux or SD, so fewer community resources, workflows, and LoRAs available yet.
Training Your Own
The MIT license extends to training:
LoRA training: Works with standard SDXL-style LoRA training pipelines. Adapt for your specific use cases.
Fine-tuning: Full fine-tuning possible if you have the compute. The sparse architecture may require adjusted training strategies.
Dataset prep: Similar requirements to other large diffusion models. High-quality paired text-image data.
Future Outlook
The HiDream team is actively developing:
- More efficient variants
- Additional editing capabilities
- Better agent integration
- Community tooling support
As a recently open-sourced model, expect rapid ecosystem development. When SDXL and Flux went public, community tooling exploded within months. Same pattern likely here.
The sparse MoE architecture also represents a trend. As models get larger, dense computation becomes unsustainable. Sparse architectures that activate only necessary capacity will become standard.
FAQ
Is HiDream better than Flux? On benchmarks, yes. For specific use cases, depends on what you're generating. Try both.
Can I run it on 8GB VRAM? Not without significant optimization. Dev variant needs 16GB minimum for comfortable usage.
Where do I download it? HuggingFace: huggingface.co/HiDream-ai/HiDream-I1-Full (and Dev, Fast variants).
Is the code open source? Yes, GitHub repository available with MIT license.
Does it work in ComfyUI? Community nodes exist. Check the ComfyUI Manager or GitHub for latest compatible nodes.
How does it compare to DALL-E 3? HiDream scores higher on benchmarks but DALL-E 3 has different strengths in certain styles. HiDream is open source; DALL-E 3 is API only.
Can I use it commercially? Yes, MIT license allows commercial use without restrictions.
What about the editing variant? HiDream-E1 extends the base model for instruction-based editing. Separate download.
Conclusion
HiDream-I1 represents a significant step in open-source image generation. The combination of benchmark-leading performance, efficient sparse architecture, and permissive MIT licensing makes it a compelling choice for both researchers and production users.
The sparse MoE approach points toward how large generative models will evolve. As we push toward even larger scales, dynamic computation allocation becomes essential. HiDream shows this architecture works exceptionally well.
If you're currently using Flux or SD3, HiDream-I1 is worth evaluating. The benchmark improvements are real, and the licensing is more permissive. The ecosystem is younger, but that's changing rapidly.
For new projects without legacy constraints, starting with HiDream makes sense. You get state-of-the-art quality with full commercial rights and an architecture designed for efficiency. That's a strong foundation.
Ready to Create Your AI Influencer?
Join 115 students mastering ComfyUI and AI influencer marketing in our complete 51-lesson course.
Related Articles

10 Best AI Influencer Generator Tools Compared (2025)
Comprehensive comparison of the top AI influencer generator tools in 2025. Features, pricing, quality, and best use cases for each platform reviewed.

5 Proven AI Influencer Niches That Actually Make Money in 2025
Discover the most profitable niches for AI influencers in 2025. Real data on monetization potential, audience engagement, and growth strategies for virtual content creators.

AI Action Figure Generator: How to Create Your Own Viral Toy Box Portrait in 2026
Complete guide to the AI action figure generator trend. Learn how to turn yourself into a collectible figure in blister pack packaging using ChatGPT, Flux, and more.