HyperLoRA: Zero-Shot Portrait Generation Without Fine-Tuning
ByteDance's HyperLoRA generates personalized LoRA weights from a single face image without training. CVPR 2025 Highlight paper with ComfyUI integration.
Make AI images and video in your browser
Characters, video, photo packs. No GPU, no setup. Your first generation is free.
Training a LoRA takes time. Collecting images, annotating them, running training for an hour, hoping the result doesn't overfit. What if you could skip all of that?
HyperLoRA, a CVPR 2025 Highlight paper from ByteDance, generates personalized LoRA weights from a single face image in seconds. No training. No dataset preparation. Just instant portrait generation with your reference.
Quick Answer: HyperLoRA is a parameter-efficient method that uses a hypernetwork to generate personalized LoRA weights directly from input face images. It achieves zero-shot personalized portrait generation with high photorealism, fidelity, and editability—no per-person training required.
- Generates personalized LoRA weights from single face image in seconds
- No fine-tuning needed—truly zero-shot operation
- Supports multiple input images via simple averaging
- Decomposes into Hyper ID-LoRA and Hyper Base-LoRA for clean separation
- Official ComfyUI integration from ByteDance
The Training Problem HyperLoRA Solves
Current personalization methods have tradeoffs:
LoRA/DreamBooth: Excellent quality, but requires training on individual samples. 10-30 minutes minimum per person. Consumes compute. Risks overfitting.
IPAdapter: Zero-shot, but often produces unnatural or uncanny results. The person looks "close" but not right.
InstantID/PhotoMaker: Better zero-shot quality, but still compromises on naturalness compared to trained approaches.
HyperLoRA bridges the gap: the quality of trained LoRA with the speed of zero-shot inference.
How HyperLoRA Works
The architecture is elegant:
Hypernetwork Approach
Instead of training LoRA weights on target images, HyperLoRA uses a pre-trained "hypernetwork" that predicts what the LoRA weights should be.
Given your input face image:
- Extract facial features via encoder
- Feed features to hypernetwork
- Hypernetwork outputs LoRA weights
- Merge predicted weights with base model
- Generate personalized images
The hypernetwork was trained on massive face data to learn the relationship between face features and optimal LoRA parameters. At inference, it applies this learned relationship instantly.
Dual-LoRA Decomposition
HyperLoRA explicitly separates identity from everything else:
Hyper ID-LoRA: Captures identity-specific features—facial structure, features, distinguishing characteristics.
Hyper Base-LoRA: Handles non-identity elements—background, clothing, pose, style.
This separation prevents "feature leakage" where irrelevant details from the reference image contaminate the identity encoding. Cleaner separation = better editability.
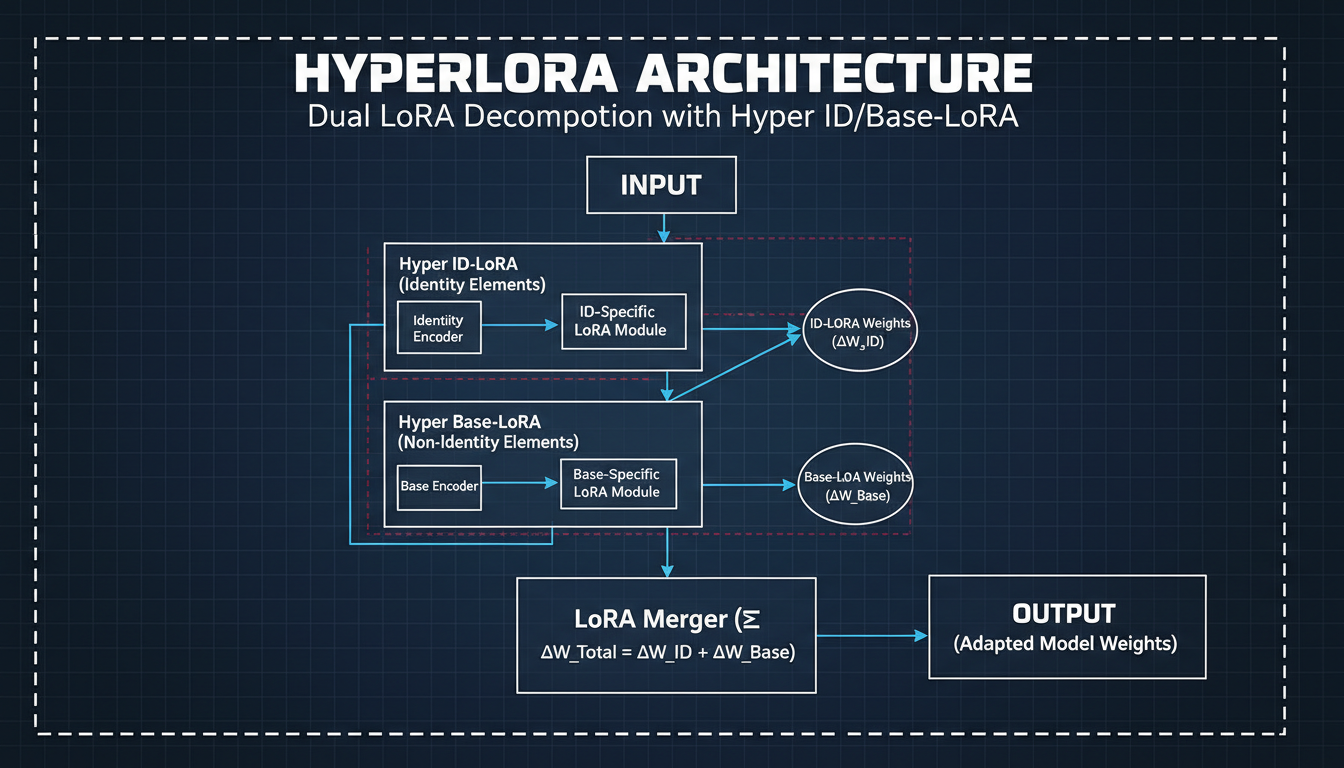 Hyper ID-LoRA captures identity while Hyper Base-LoRA handles non-identity elements
Hyper ID-LoRA captures identity while Hyper Base-LoRA handles non-identity elements
ComfyUI Integration
ByteDance released an official ComfyUI implementation.
Installation
cd ComfyUI/custom_nodes
git clone https://github.com/bytedance/ComfyUI-HyperLoRA
pip install -r ComfyUI-HyperLoRA/requirements.txt
Model Download
Two model versions available:
sdxl_hyper_id_lora_v1_fidelity- Optimized for faithful reproductionsdxl_hyper_id_lora_v1_edit- Optimized for editability/variation
Place models in ComfyUI/models/hyperlora/.
Basic Workflow
- Load Image → Your reference face
- HyperLoRA Encoder → Extracts face features
- HyperLoRA LoRA Predictor → Generates weights
- Apply LoRA → Merges with base SDXL model
- KSampler → Generates new image
- Save Image → Output
The workflow is simpler than training workflows because there's no training step.
Compatible Base Models
HyperLoRA works with specific SDXL checkpoints. Tested compatibility:
Free ComfyUI Workflows
Find free, open-source ComfyUI workflows for techniques in this article. Open source is strong.
Works well:
- LEOSAM's HelloWorld XL 3.0
- CyberRealistic XL v1.1
- RealVisXL v4.0 (often best results)
Incompatible:
- ArienMixXL v4.0
- Some heavily merged checkpoints
If results look wrong, try a different base model before debugging elsewhere.
Single vs Multiple References
Single Image
One face image produces good identity capture. Fast and simple. Ideal for quick tests or when only one reference is available.
Multiple Images
When you have multiple face images:
- Process each through HyperLoRA encoder
- Average the resulting LoRA weights
- Apply averaged weights
This leverages LoRA's natural interpolability. Multiple references reduce variance and improve consistency across generated images.
In my testing, 3-5 reference images from different angles produces noticeably more stable identity than single reference.
 Multiple reference images produce more stable and consistent identity
Multiple reference images produce more stable and consistent identity
Fidelity vs Editability
The two model versions offer different tradeoffs:
Want to skip the complexity? Apatero gives you professional AI results instantly with no technical setup required.
Fidelity Model
sdxl_hyper_id_lora_v1_fidelity
- Maximum likeness preservation
- Less responsive to prompt modifications
- Best for faithful reproductions
Use when: You need the person to look exactly like the reference.
Edit Model
sdxl_hyper_id_lora_v1_edit
- Better prompt responsiveness
- More variation in outputs
- Slightly less strict identity matching
Use when: You want the general likeness but need flexibility in pose, expression, or style.
Comparison to Alternatives
| Method | Training Time | Quality | Editability |
|---|---|---|---|
| LoRA Training | 20-60 min | Excellent | Good |
| DreamBooth | 30-60 min | Excellent | Moderate |
| IPAdapter | 0 (zero-shot) | Moderate | Good |
| InstantID | 0 (zero-shot) | Good | Moderate |
| HyperLoRA | 0 (zero-shot) | Excellent | Good |
HyperLoRA achieves training-quality results without training time. The main tradeoff is requiring specific compatible base models.
Practical Applications
Content Creation at Scale
Generate consistent character content without maintaining trained LoRAs. Each new face is a few seconds of processing, not an hour of training.
Real-Time Personalization
Apps that need instant personalization—photo booths, AR filters, marketing personalization—become practical with zero-shot processing.
Character Variation
Create multiple variations of a character across poses, styles, and scenarios without the rigidity that trained LoRAs sometimes exhibit.
Quick Testing
Before committing to full LoRA training, test if a face works well with AI generation. HyperLoRA provides instant feedback.
Earn Up To $1,250+/Month Creating Content
Join our exclusive creator affiliate program. Get paid per viral video based on performance. Create content in your style with full creative freedom.
Tips for Best Results
High quality reference: Clear, well-lit, front-facing photos work best. Low quality in = low quality out.
Minimal occlusion: Avoid glasses, hats, or hands covering the face unless you want those in output.
Neutral expression: Extreme expressions can affect identity capture. Neutral works most reliably.
Match aspect ratio: Use similar aspect ratios between reference and output for best results.
Experiment with models: Try both fidelity and edit versions. Results vary by face and use case.
Current Limitations
SDXL only: No SD 1.5 or FLUX support currently.
Limited base models: Only specific checkpoints are compatible.
Face-focused: Designed for portraits, not full-body or non-face personalization.
Single identity: Designed for one identity at a time. Multi-person scenes need separate processing.
Integration with Other Techniques
With ControlNet: Use HyperLoRA for identity, ControlNet for pose. They're complementary.
With IPAdapter: IPAdapter for style, HyperLoRA for face. Combine for styled portraits.
With AnimateDiff: Animate HyperLoRA-personalized images for character animation.
FAQ
Is HyperLoRA free to use? The research and code are open. Check ByteDance's license for commercial use terms.
How does quality compare to trained LoRA? Very close. Slight differences exist, but for most applications they're equivalent.
Can I use my own training data? The hypernetwork is pre-trained. You don't need training data—that's the point.
Does it work with video? HyperLoRA is image-based. For video, generate frames or integrate with video pipelines.
What about privacy? Face images are processed locally in your ComfyUI. Nothing is uploaded unless you choose to.
Can I combine multiple identities? Averaging LoRAs from different identities creates blends. Not multi-identity scenes, but morphs.
The CVPR 2025 Context
HyperLoRA was accepted as a CVPR 2025 Highlight—top tier academic recognition. The paper demonstrates rigorous evaluation against prior methods with clear improvements.
This isn't a weekend project or speculative approach. It's research-grade work that happens to have practical implementation.
For Apatero.com, methods like HyperLoRA point toward a future where personalization is instant and accessible. Training infrastructure becomes optional when models can generalize on the fly.
The gap between "what research can do" and "what practitioners can use" is narrowing fast.
Make AI images and video in your browser
Characters, video, photo packs. No GPU, no setup. Your first generation is free.
Related Articles

10 Best AI Influencer Generator Tools Compared (2025)
Comprehensive comparison of the top AI influencer generator tools in 2025. Features, pricing, quality, and best use cases for each platform reviewed.

5 Proven AI Influencer Niches That Actually Make Money in 2025
Discover the most profitable niches for AI influencers in 2025. Real data on monetization potential, audience engagement, and growth strategies for virtual content creators.

AI Action Figure Generator: How to Create Your Own Viral Toy Box Portrait in 2026
Complete guide to the AI action figure generator trend. Learn how to turn yourself into a collectible figure in blister pack packaging using ChatGPT, Flux, and more.